
When learning a child you compare words with what they can recognize.
A machine can calculate efficiently / recognize if a formula is correct.
To use it as a strength, we can build it learning formulas.

Web module to write formulas:
https://github.com/susam/texme
https://opendocs.github.io/texme/examples/demo.html
We can start introducing memory via common variables.
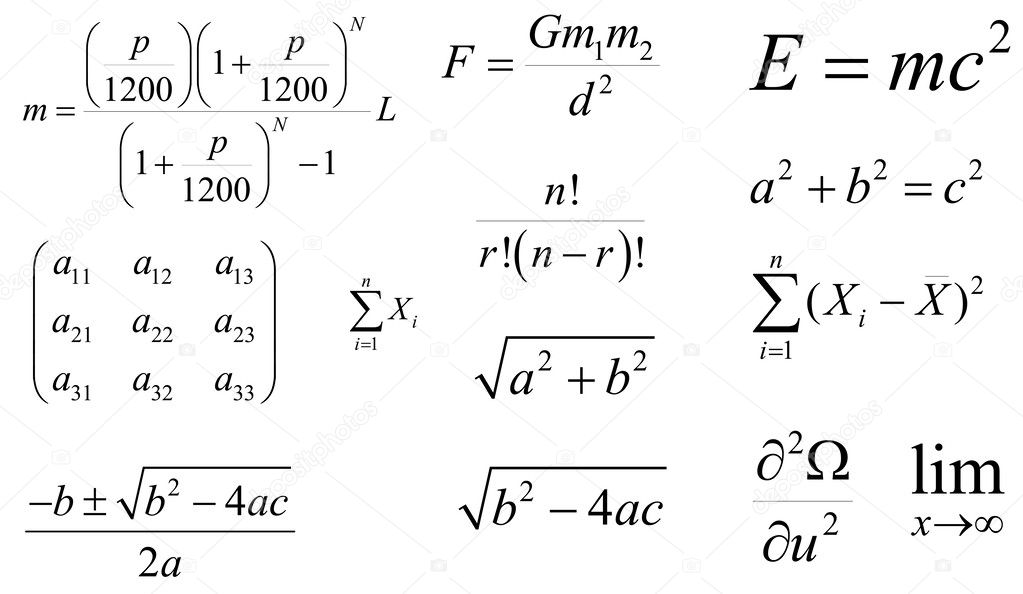
Labels: Symbols
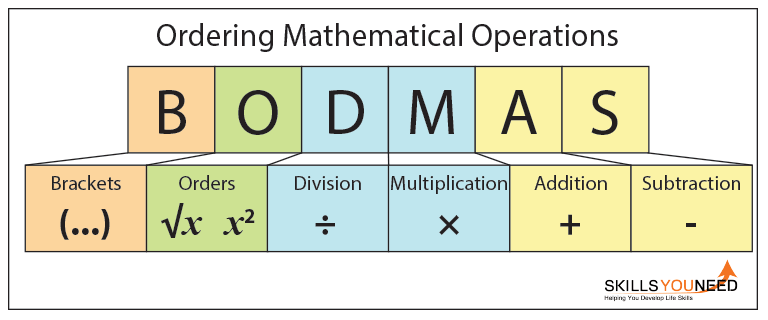
Features: Position in formula by calculation order of operations.
https://www.mathsisfun.com/algebra/operations-order-calculator.html
Then save the formula in a vector.
We'll need to simplify the formula first.
Python Sympy can do this for us.
Storing into a numpy array we'll need numbers to represent a symbol/amount.
The value is only a category so its specific feature amount will not make a difference. The formula will be remembered. These will get messy as the amount and variety are immense. For ease of understanding we may update the values later and retrain.
We can add these:
https://ned.ipac.caltech.edu/level5/Units/frames.html
http://asciimath.org/
https://physics.info/equations/
| Equation | Training value |
|---|---|
| Nothing | 0 |
| ( | 1 |
| ) | 2 |
| power | 3 |
| devide | 4 |
| multiply | 5 |
| add | 6 |
| subtract | 7 |
| 0 | 8 |
| 1 | 9 |
| 2 | 10 |
| 3 | 11 |
| 4 | 12 |
| 5 | 13 |
| 6 | 14 |
| 7 | 15 |
| 8 | 16 |
| 9 | 17 |
| deca | 18 |
| hecto | 19 |
| kilo | 20 |
| mega | 30 |
| giga | 40 |
| tera | 50 |
| ... | |
| m | 70 |
| g | 71 |
| ... |
import numpy as np
dataset = {}
dataset['target_name'] = np.array(['', 'Deca', 'Hecto', 'Weight'])
dataset['feature_name'] = np.array(['equasion_pos1', 'equasion_pos2', 'equasion_pos3', 'equasion_pos4', 'equasion_pos5'])
#Prep dataset container
dataset['features'] = np.array([0, 0, 0, 0, 0]).astype('int')
dataset['target'] = np.array([0]).astype('int')
#Deca or 10
#1deca
dataset['features'] = np.vstack([dataset['features'], np.array([9, 18, 0, 0, 0])])
dataset['target'] = np.append (dataset['target'], [1])
#Weight
#m multiply g
dataset['features'] = np.vstack([dataset['features'], np.array([70, 5, 71, 0, 0])])
dataset['target'] = np.append (dataset['target'], [3])
print(dataset['features'])
print(dataset['target'])